Song Recommender
Für unsere Musikempfehlungen wurden acht zufällig ausgewählte Personen auf dem Dorfplatz einer kleinen Gemeinde befragt. Sie gaben ihren Namen, ihr Geschlecht, Alter und ihr Lieblingslied an. Diese Informationen wurden in einer Tabelle erfasst. Anschließend entwickelten wir einen Algorithmus, der diese Daten verwendet, um basierend auf den Benutzereingaben eine angepasste Songempfehlung zu geben.
Reflektiere einmal: Wie zufrieden warst du mit deiner Empfehlung? Vergleiche diese mit den Empfehlungen für die andere Gruppe. Wer könnte deiner Meinung nach zufriedener mit den Empfehlungen sein?
Datensatz
Unten siehst du die Ergebnisse unserer Straßenumfrage:
| Name | Geschlecht | Alter | Lieblingslied |
|---|---|---|---|
| Manfred | m | 81 | Marmor, Stein und Eisen bricht |
| Lia | w | 14 | Flowers |
| Peter | m | 90 | Er gehört zu mir |
| Josef | m | 73 | Über den Wolken |
| Elin | w | 21 | Tattoo |
| Franz | m | 81 | Aber bitte mit Sahne |
| Elena | w | 17 | I’m Good (Blue) |
| Alina | w | 13 | Sprinter |
| Walter | m | 72 | Tulpen aus Amsterdam |
| Mila | w | 19 | Daylight |
A1 – Warum unterscheidet sich die Qualität der Empfehlungen zwischen den beiden Geschlechtsgruppen so stark?
Unser Algorithmus generiert Vorschläge basierend auf dem Geschlecht der Nutzer. Er vergleicht das Geschlecht des Benutzers mit der Geschlechtskategorie in unserem Datensatz und liefert dann alle Songs, die von Personen des gleichen Geschlechts als Lieblingslied angegeben wurden. Diese Art der Datenorganisation aufgrund von Übereinstimmungen wird Klassifizierung genannt. Warum denkst du, dass diese Art der Klassifizierung in unserem Fall nicht optimal funktioniert?
Visualisierung
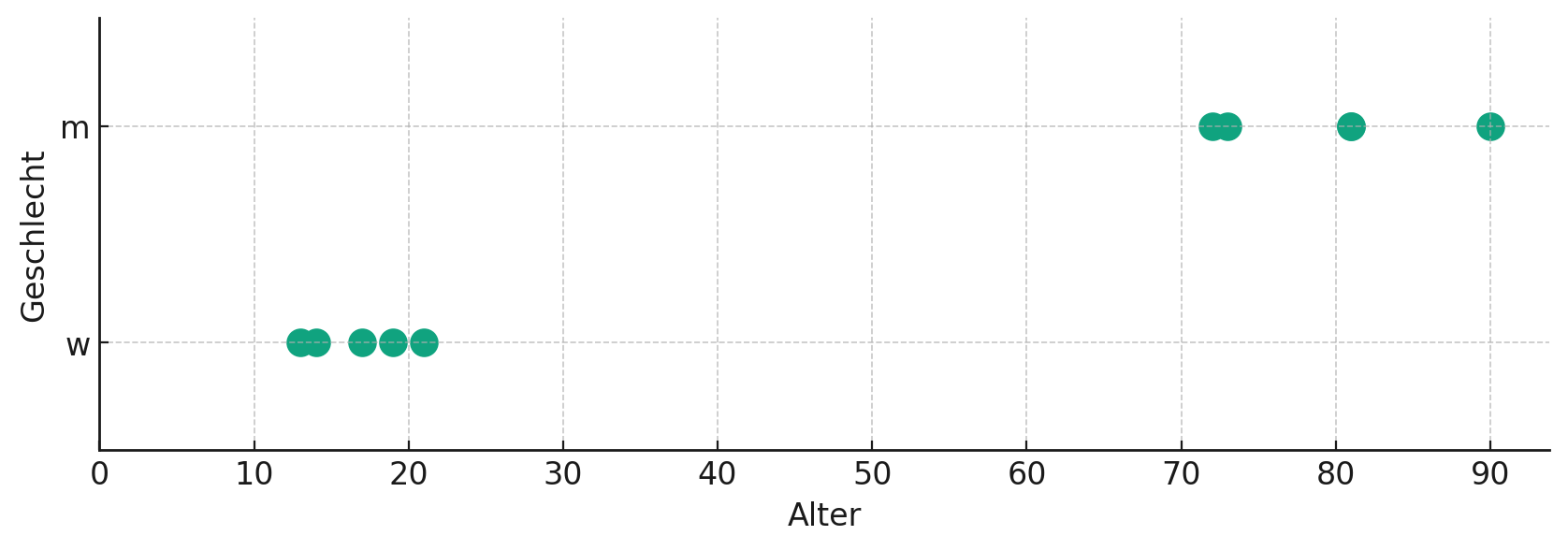
Umfrageergebnisse geordnet nach den Merkmalen Geschlecht und Alter. Die grünen Punkte repräsentieren die einzelnen Antworten. Diese Darstellung wird als Streudiagramm bezeichnet.
A2 – In der oben gezeigten Darstellung sind die Daten aus unserem Datensatz als Streudiagramm abgebildet. Wie könnte man die Qualität der Empfehlungen verbessern, ohne den Datensatz zu ändern?
Wie wir festgestellt haben, waren alle männlichen Teilnehmer der Umfrage signifikant älter als die weiblichen Teilnehmer. Daher ist das Geschlecht vielleicht nicht das beste Kriterium, um den Musikgeschmack zu bestimmen.
Wir könnten die Qualität der Empfehlungen verbessern, indem wir das Alter als Kriterium für die Klassifizierung verwenden. Wie im Streudiagramm ersichtlich, könnte eine Trennlinie bei einem Alter von 50 Jahren gezogen werden, um zwei Altersgruppen zu erstellen, anstatt die Geschlechtsgruppen zu verwenden. Wir müssten allerdings die Eingangsfrage des "Song Recommenders" anpassen. Wie könnte diese aussehen? (Musterlösung)
Moderne Empfehlungssysteme, wie du sie von Plattformen wie YouTube, TikTok, Spotify und anderen kennst, sind natürlich viel komplexer gestaltet (opens in a new tab). Grundsätzlich verfahren sie jedoch ähnlich: Nutzer werden basierend auf den Eigenschaften der von ihnen konsumierten Inhalte in verschiedene Geschmacksgruppen eingeteilt. In unserem ersten Beispiel haben wir eine Klassifizierung anhand eines einzigen Merkmals vorgenommen (zuerst Geschlecht, dann Alter). Das hat allerdings noch nicht viel mit künstlicher Intelligenz zu tun. In der nächsten Übung verwenden wir überwachtes Lernen, um einer Maschine beizubringen, Filmempfehlungen für verschiedene Geschmacksgruppen zu geben.